Oracle - Group Functions
Some examples of my work as a teaching assistant, talking about the group functions.
Oracle Group Functions
Why do we need Group Functions?
Take the below table as example:
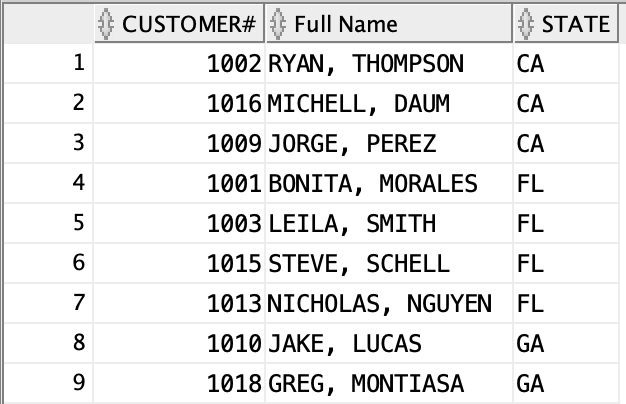
You may want to group them by the STATE .
select state from customers group by state order by state;
As you can see, in the previous table, we have 3 rows of state CA. But in the below table, we only have 1.
It means that, when we are doing group by , some data just get lost. So if you are trying to do like this:
select firstname, state from customers group by state order by state;Error could happen:
ORA-00979: not a GROUP BY expression
00979. 00000 - "not a GROUP BY expression"
*Cause:
*Action:
Error at Line: 73 Column: 8To explain what's going on here in a relatively simple way, we can say that as you may lose data when you are doing group by if you select other column other than the grouped column STATE. Oracle do not like this and also it cannot judge which data to lose.
That's why you are going to use group function to "Aggregate" them together.
select count(*) "count", state from customers group by state order by state;There are so many Group Functions mentioned in the lab material, I'm not going to run all of them. But I do love to share one function I loved.
select listagg(firstname || ', ' || lastname) "All Customers", state from customers group by state order by state;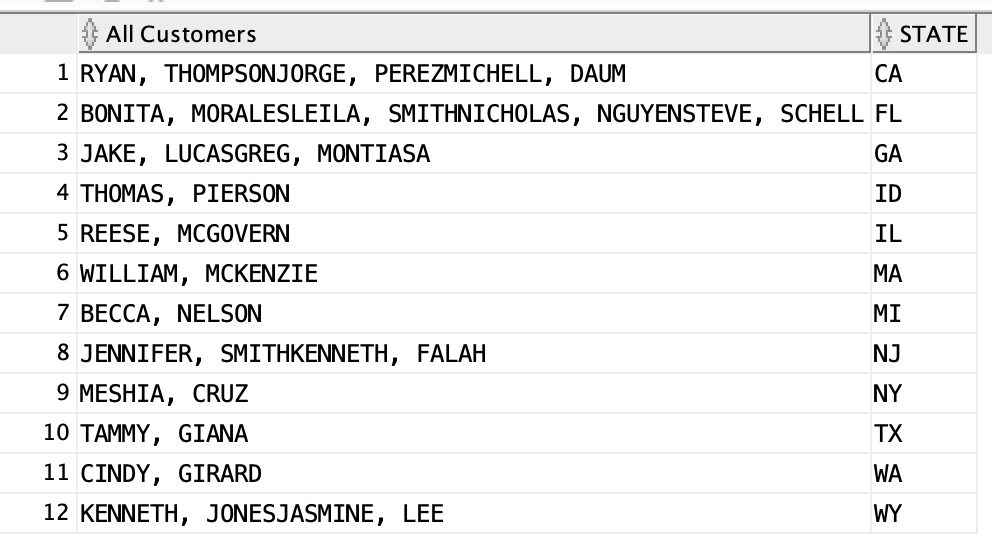
As you can see, this is to combine all the names in the group so that you lose no data.
Grouping Sets
https://www.oracletutorial.com/oracle-basics/oracle-grouping-sets/
We are going to analyze what the below statement is doing:
select name, category, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
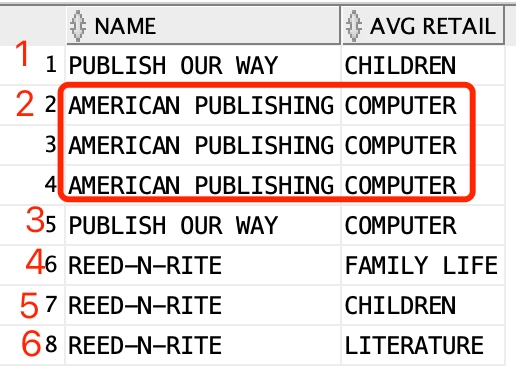
group by grouping sets (name, category, (name, category),());Firstly, we may want to see the output:
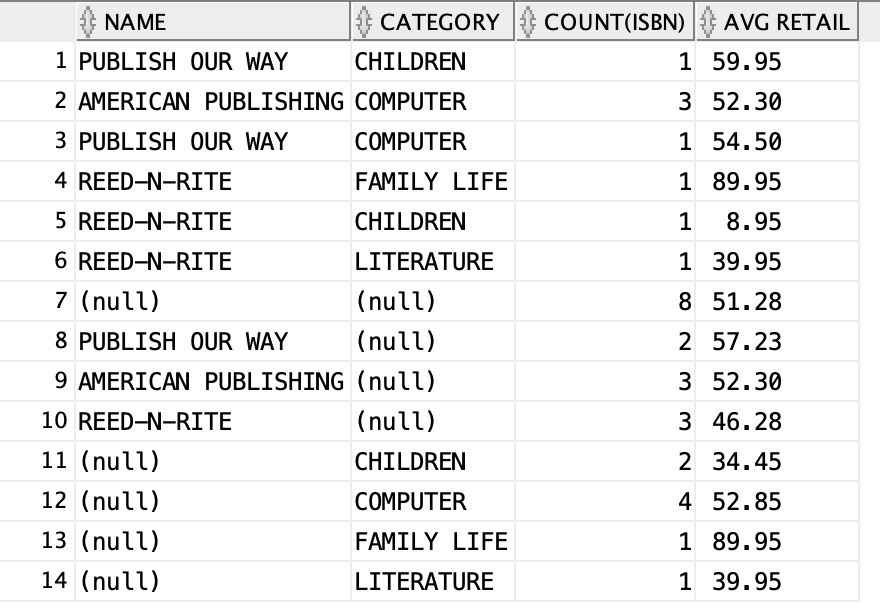
It looks weird, and then we are going to do some analysis:
Firstly, what are we unfamiliar with?
group by grouping sets (name, category, (name, category),());So we just remove them and try to run the rest:
select name, category "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5);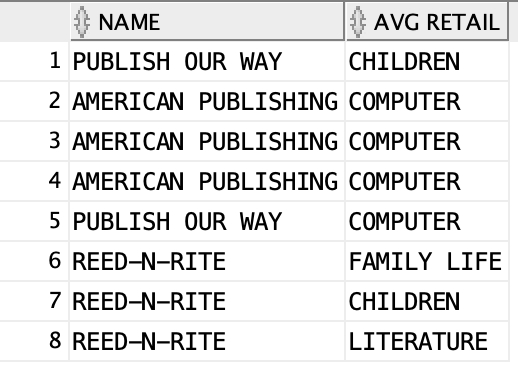
Here we got something related to the previous image. This is to show all the name and category.
So what if we run something else?
select name, category, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
group by grouping sets (name, category);And we get:

It looks like the grouping sets (name, category) is going to combine the result of group by name and group by category
If we keep running like this, we can find that do is to combine the group by result together by adding all the rows.
To be mentioned, we will get the below output when we run:
group by name, category

compare with the original data, we can find this means we are doing something like "adding name and category together to be a new attribute and use that to group the result".
Another thing is the () in the groupping sets,
A grouping sets may include zero column. In this case, it is an empty grouping set, which is denoted by
().[^1]
Cube
In addition to the subtotals generated by the
ROLLUPextension, theCUBEextension will generate subtotals for all combinations of the dimensions specified. If "n" is the number of columns listed in theCUBE, there will be 2n subtotal combinations.[^2]
This means that find out all the possible combinations with the given group attributes.
So the below statements works the same way:
select name, category, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
group by grouping sets (name, category, (name, category),());
select name, category, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
group by cube (name, category);The advantage of groupping sets can be it doesn't necessarily take all possible combinations of the columns.
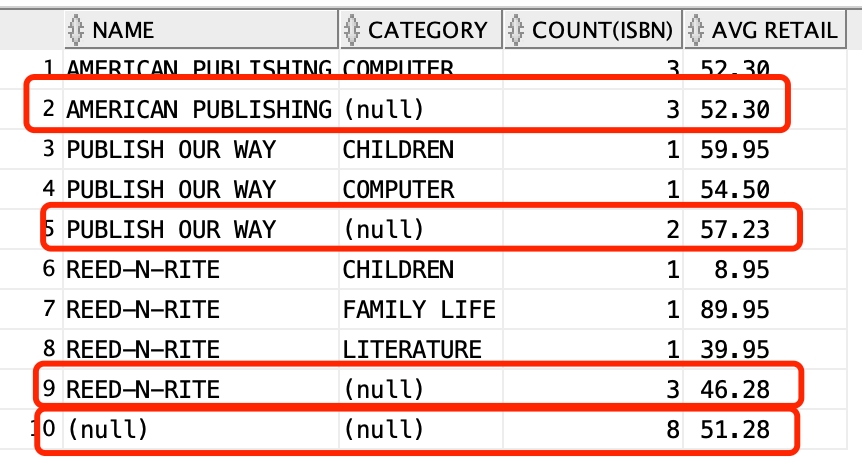
Rollup
select name, category, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
group by rollup (name, category)
order by name, category;Below we see the output:
If you find difficult to understand what rollup is doing, you can also run this:
select name, count(isbn), to_char(avg(retail), '99.99') "AVG RETAIL"
from publisher join books using (pubid)
where pubid in (2,3,5)
group by name
order by name;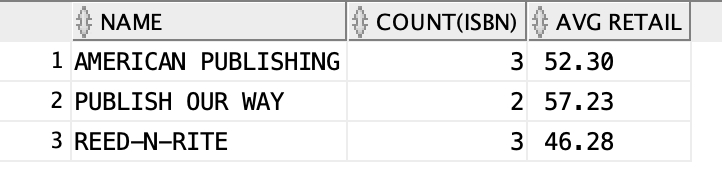
See the similarity?
rollup is going to calculate an extra group result for the first column to be grouped.
You can check this link for more detailed explanation: https://www.oracletutorial.com/oracle-basics/oracle-rollup/
Reference:
Last updated